高并发与海量数据处理 架构设计与CSDN博客的实践
在当今互联网时代,无论是电商平台的秒杀活动,还是社交媒体平台的实时信息流,亦或是像CSDN这样的技术博客社区,高并发与海量数据处理都已成为后端系统设计必须面对的核心挑战。本文将以技术社区为背景,探讨应对这些挑战的关键技术与服务架构。
一、高并发处理的核心理念
高并发指的是系统在短时间内处理大量用户请求的能力。对于CSDN这类博客平台,热门文章的瞬间访问、评论区的实时互动都构成了典型的并发场景。应对高并发,关键在于:
- 负载均衡:通过Nginx、HAProxy等工具,将流量合理分发到多个后端服务器,避免单点过载。
- 缓存为王:利用Redis、Memcached等内存数据库,将频繁读取的热点数据(如文章摘要、热门榜单)缓存起来,极大减轻数据库压力。这是应对瞬时高并发的第一道防线。
- 服务解耦与异步化:将核心服务(如文章浏览)与非核心或耗时服务(如文章阅读数统计、消息通知)分离。通过消息队列(如Kafka、RocketMQ)实现异步处理,提升主流程的响应速度。
二、海量数据处理的存储策略
海量数据不仅指用户生成的文章、评论等内容数据,还包括用户行为日志、系统监控数据等。其处理核心在于存储与计算的扩展性。
- 数据库分库分表:当单表数据量达到千万级,读写性能会急剧下降。通过水平拆分(如按用户ID或时间范围),将数据分布到多个数据库实例和表中,是关系型数据库(如MySQL)应对海量数据的经典方案。
- 异构数据存储(多模数据库):
- 核心事务数据:仍由MySQL等关系数据库处理,保证ACID特性。
- 文档型内容:博客文章、评论等半结构化数据,适合使用Elasticsearch(提供全文搜索)或MongoDB存储,便于灵活扩展和复杂查询。
- 时序数据:监控指标、访问日志等,可使用时序数据库如InfluxDB、TDengine,它们对时间序列数据的写入和聚合查询有极高优化。
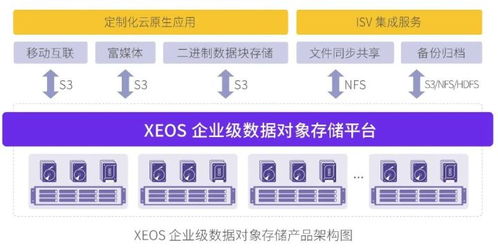
- 对象存储服务:对于博客中的图片、视频、用户头像等非结构化大数据,应使用OSS(如阿里云OSS、腾讯云COS)进行存储,它们成本低廉、扩展无限,并通过CDN加速分发。
三、数据处理与存储服务的架构演进
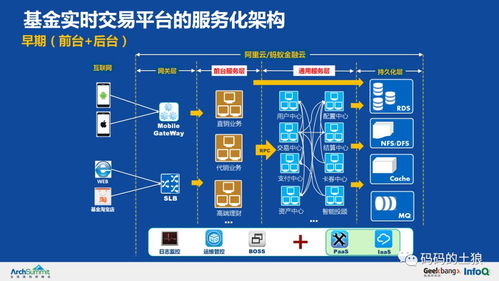
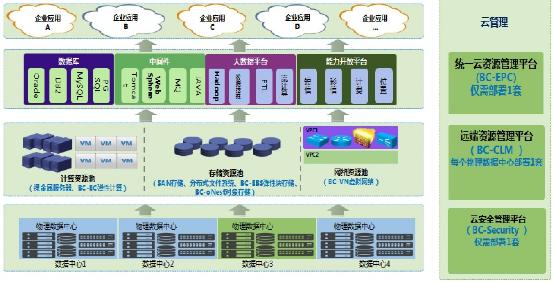
一个成熟的平台如CSDN,其数据处理架构通常是分层的:
- 接入层:负责流量承接、安全防护和静态资源加速(CDN)。
- 应用服务层:由多个微服务构成,每个服务独立负责特定功能(用户服务、文章服务、评论服务)。它们通过RPC或RESTful API通信,并大量使用本地缓存和分布式缓存。
- 数据存储层:即上述的异构存储集群,是系统的“数据湖”。
- 大数据处理层:此层是海量数据价值的挖掘中心。通过Flume、Logstash等工具将日志、行为数据采集到大数据平台(如Hadoop HDFS或云上数据湖)。利用Spark、Flink进行实时或离线计算,分析用户行为、生成内容推荐、进行运营统计,结果可写回存储层供业务系统使用。
四、CSDN博客场景下的实践思考
对于技术博客社区,除了通用架构,还需特别关注:
- 文章搜索与推荐:高度依赖Elasticsearch实现毫秒级全文检索和复杂筛选(如按标签、作者)。结合用户浏览历史,利用机器学习模型进行个性化文章推荐,是提升留存的关键。
- 实时互动体验:评论区的高并发实时更新,可通过WebSocket结合消息队列实现,并将最新评论缓存在Redis中。
- 代码片段与文件处理:技术博客常包含代码,需要专门的语法高亮服务和代码存储服务,并与文章主体解耦。
###
高并发与海量数据处理没有银弹,它是一个在性能、成本、复杂度与业务需求之间持续权衡和演进的过程。从CSDN这类成熟平台的实践来看,成功的核心在于采用分布式、分层化、异步化的架构思想,并灵活运用缓存、队列、异构数据库及大数据技术栈。随着云原生和Serverless技术的发展,未来开发者可以更聚焦业务逻辑,而将弹性伸缩、数据持久化等复杂性更多地托付给云服务,从而更高效地构建稳定、可扩展的互联网应用。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/45.html
更新时间:2026-06-19 14:42:21