深入HBase存储模型 大数据中最具挑战的源码解析
HBase作为大数据生态系统中的核心组件,其存储模型的设计与实现是众多开发者和架构师深感棘手的难点之一。本文将聚焦HBase的存储架构、数据处理逻辑及服务机制,解析其源码中的关键挑战点。
一、存储模型概述
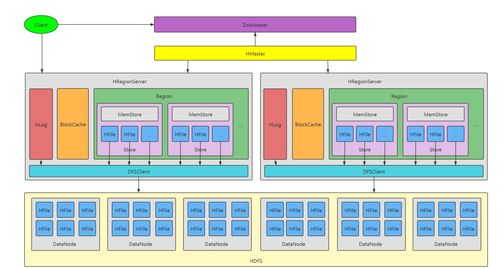
HBase基于Google Bigtable的设计思想,采用LSM-Tree(Log-Structured Merge-Tree)作为底层存储结构。其存储模型主要包含以下核心组件:
- Region:数据分片的基本单元,每个Region负责存储一段连续的行键范围。
- Store:对应于一个列族(Column Family)的存储单元,每个Store包含一个MemStore和多个HFile。
- HFile:实际存储数据的文件格式,基于HDFS实现持久化。
二、数据处理流程
HBase的数据写入流程遵循LSM-Tree的原则:
- 写入操作首先被记录到WAL(Write-Ahead Log)以确保数据持久性。
- 数据随后被写入MemStore(内存缓冲区),当MemStore达到阈值时,会触发Flush操作,将数据持久化为HFile。
- 后台的Compaction进程会定期合并小的HFile,以减少读取时的I/O开销,并清理过期数据。
数据读取则涉及多层查询:
- 首先检查BlockCache(读缓存)。
- 若未命中,则依次搜索MemStore和HFile,通过布隆过滤器(Bloom Filter)快速判断数据是否存在。
三、源码难点解析
HBase存储模型的源码实现中,最具挑战的部分包括:
- Region分裂与合并:如何动态调整数据分布,同时保证服务的高可用性。
- Compaction策略:权衡I/O消耗与查询性能,避免『写放大』问题。
- 内存管理:MemStore与BlockCache的协同,防止JVM堆内存溢出。
- 分布式事务:基于MVCC(多版本并发控制)的处理机制,保障数据一致性。
四、存储服务优化
为应对海量数据的存储与访问需求,HBase在服务层做了多项优化:
- 利用HDFS的冗余机制保障数据可靠性。
- 通过RegionServer的负载均衡,避免单点瓶颈。
- 支持协处理器(Coprocessor),允许用户自定义数据处理逻辑。
HBase的存储模型通过LSM-Tree的巧妙设计和分布式架构的支撑,实现了高吞吐量的数据写入与灵活的数据查询。其源码中复杂的线程调度、资源管理和异常处理机制,正是开发者需要深入理解和攻克的难点。对于希望精通大数据存储技术的从业者来说,透彻掌握HBase的存储模型源码,无疑是提升技术深度的关键一步。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/26.html
更新时间:2026-06-19 23:44:59