分布式文件存储SeaweedFS的数据存储设计与实现
随着大数据和云计算的快速发展,数据处理和存储服务已成为现代信息技术架构的核心组成部分。传统集中式存储系统在面对海量数据存储和高并发访问需求时,往往显得力不从心。在这一背景下,分布式文件存储系统应运而生,而SeaweedFS作为其中的佼佼者,以其简洁的设计和高效的性能赢得了广泛关注。
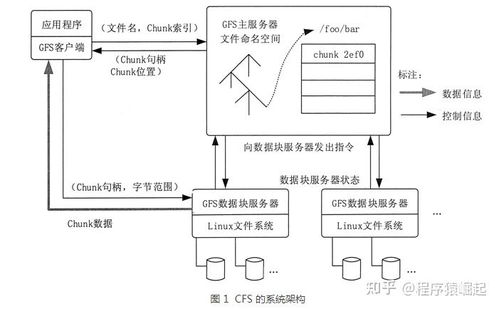
SeaweedFS的设计灵感来源于Google File System(GFS),但采用了更轻量级的架构。其核心设计理念是将元数据管理与数据存储分离,通过一个主控节点(Master)管理文件卷(Volume)的元数据,而多个卷服务器(Volume Server)负责实际的数据存储。这种设计不仅降低了单点故障的风险,还提高了系统的扩展性和容错能力。
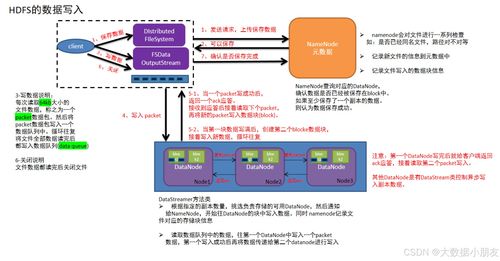
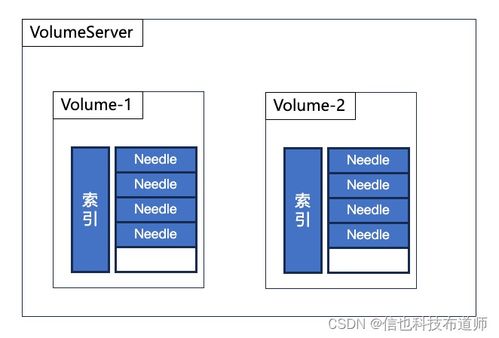
在数据存储的实现方面,SeaweedFS采用了一种称为“卷”的逻辑单元来组织数据。每个卷可以存储多个文件,并通过唯一的文件ID进行标识。当客户端需要存储文件时,首先向主控节点请求一个可用的卷服务器和文件ID,然后直接将文件数据写入指定的卷服务器。这种直接写入机制避免了元数据操作的瓶颈,显著提升了存储效率。
SeaweedFS支持数据的自动复制和负载均衡。通过配置复制因子,系统可以在多个卷服务器之间自动创建数据副本,确保数据的高可用性和持久性。同时,主控节点会监控各卷服务器的负载情况,动态调整数据分布,以优化存储资源的利用率。
对于数据处理服务,SeaweedFS提供了灵活的接口,支持与Hadoop、Spark等大数据框架集成。用户可以通过RESTful API或FUSE挂载方式访问存储的数据,实现无缝的数据处理流水线。这种兼容性使得SeaweedFS不仅适用于传统的文件存储场景,还能胜任大规模数据分析任务。
SeaweedFS通过其创新的数据存储设计与实现,为现代数据处理和存储服务提供了一种高效、可靠的解决方案。其简洁的架构、出色的性能以及良好的可扩展性,使其成为分布式存储领域的重要选择。随着技术的不断演进,SeaweedFS有望在更多应用场景中发挥关键作用,推动数据驱动型业务的发展。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/14.html
更新时间:2025-11-28 23:58:05