HDFS大规模数据存储底层原理详解 数据处理与存储服务
HDFS(Hadoop分布式文件系统)是专为大规模数据处理设计的分布式存储系统。在数据处理和存储服务中,HDFS通过其底层架构实现了高吞吐量、高容错性和可扩展性。
其核心原理包括以下几个方面:
- 数据分块与分布存储:HDFS将大文件分割为固定大小的块(默认128MB),这些块被分布存储在集群的多个数据节点上。这种机制不仅提高了数据访问的并行性,还增强了系统的负载均衡能力。
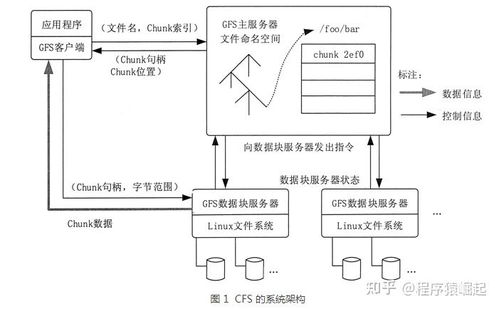
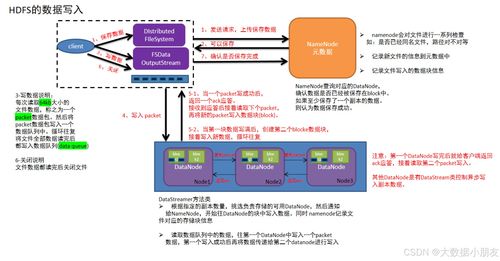
- 主从架构与元数据管理:HDFS采用主从架构,包括一个NameNode(主节点)和多个DataNode(从节点)。NameNode负责管理文件系统的命名空间和元数据(如文件块的位置、权限等),而DataNode负责实际存储数据块,并通过心跳机制定期向NameNode汇报状态。
- 数据复制与容错机制:HDFS通过数据块的副本复制(默认3个副本)来保障数据的可靠性。副本被策略性地分布在不同的机架和节点上,防止单点故障导致的数据丢失。当某个DataNode失效时,系统会自动从其他副本恢复数据。
- 数据读写流程:
- 写入流程:客户端向NameNode请求写入文件,NameNode分配数据块和DataNode位置,客户端直接将数据写入第一个DataNode,并由该节点负责将数据流水线复制到其他副本节点。
- 读取流程:客户端从NameNode获取文件块位置信息,然后直接与相应的DataNode通信读取数据,实现高吞吐量的数据访问。
- 数据处理服务集成:HDFS与MapReduce、Spark等计算框架紧密集成,支持数据的本地化处理(数据就近计算),减少网络传输开销,提升整体数据处理效率。
HDFS的设计充分考虑了大规模数据场景下的存储需求,通过分布式、冗余和并行机制,为上层应用提供了稳定、高效的数据处理与存储服务基础。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/20.html
更新时间:2025-11-28 21:28:08