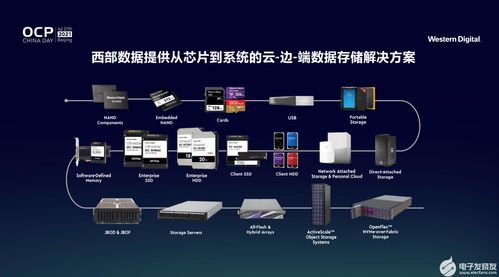
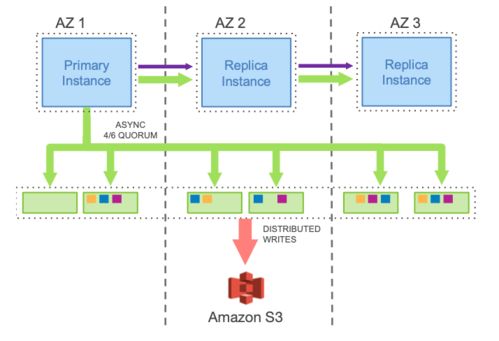
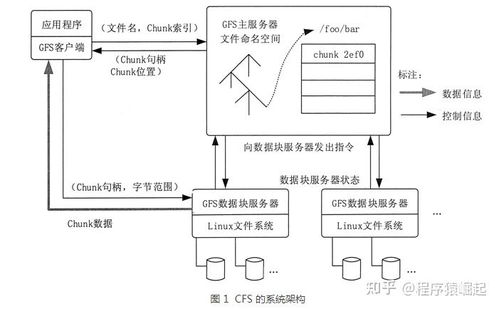
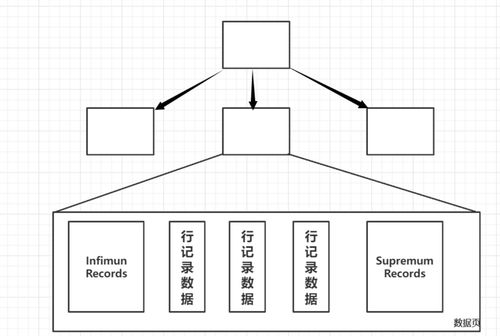
从单机到分布式数据库存储系统的演进 数据处理与存储服务的变革之路
随着信息技术的飞速发展,数据处理和存储系统经历了从单机到分布式的根本性变革。这一演进不仅反映了计算需求的快速增长,也体现了对高可用性、可扩展性和容错性的追求。
一、单机数据库时代
在早期,数据处理主要依赖单机数据库系统。这类系统将所有数据集中存储在一台服务器上,采用关系型数据库模型(如MySQL、Oracle),事务处理遵循ACID原则。单机数据库的优点是架构简单、易于管理,且能保证强一致性。随着数据量的增长和并发访问需求的提升,单机系统很快面临性能瓶颈、单点故障和扩展性限制等问题。
二、分布式数据库的兴起
为应对单机系统的局限性,分布式数据库应运而生。其核心思想是将数据分散到多台服务器上,通过网络协同工作。分布式系统通过数据分片、副本机制和负载均衡技术,实现了水平扩展和高可用性。典型的例子包括Google的Bigtable、Amazon的DynamoDB,以及开源的Cassandra和MongoDB。这些系统在设计时注重分区容错性,并在此基础上权衡一致性和可用性(如CAP理论)。
三、数据处理服务的演进
与存储系统并行,数据处理服务也从集中式向分布式发展。早期,数据处理依赖于单机上的ETL工具和批处理作业。随着大数据时代的到来,分布式计算框架如Hadoop和Spark成为主流,它们能够对海量数据进行并行处理。流处理技术(如Apache Kafka和Flink)使得实时数据分析成为可能,进一步推动了数据处理服务的演进。
四、云原生与未来趋势
云原生技术推动了数据库和存储服务的进一步革新。云数据库服务(如AWS Aurora、Google Spanner)提供了弹性伸缩、全球分布和多租户支持。存储与计算分离的架构(如Snowflake)实现了资源的高效利用。随着人工智能和边缘计算的发展,分布式系统将更加智能化和去中心化,支持更复杂的异构数据处理需求。
结语
从单机到分布式,数据库存储系统的演进不仅是技术的飞跃,更是应对数据爆炸和业务多样化的必然选择。这一历程彰显了技术创新在提升数据处理能力、保障服务可靠性方面的核心作用,为数字化时代的持续发展奠定了坚实基础。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/24.html
更新时间:2025-11-28 19:32:10